
by | | blog
A large-scale dataset stored in an Enterprise DB (usually Oracle) with a multi-TB volume of binary data, represents a fantastic opportunity for huge cost savings using DBcloudbin but, at the same time, is a challenging scenario as in any massive data migration project out there. We need to massive-data-migration-automation. We will do a introduction to this scenario in this post and how DBcloudbin automation framework is able to handle all the process.
Let’s assume we have a large scale database with TBs of binary data and we have successfully installed DBcloudbin. For a quick introduction on the solution basics, check our DBcloudbin for dummies post; for high-level overview on the install process, check here; for the complete details, you can register and get the install guide.
With the solution implementation we get a functional environment where the customer application is able to access the data from the database as before, regardless of whether the data is hosted inside the database or moved out to a more efficient and cheaper object storage. However, after implementation we have 100% of the data still hosted at database, so we have to do the ‘heavy lifting’ of moving all our binary dataset. In a regular DBcloudbin implementation we will typically define a data migration rule to be executed recurrently (usually daily) for moving the data based on our specific business rule (e.g., reports with status ‘X’ and more than ‘y’ days old). This is fine for dealing with the new data that lands in our environment in a daily basis but for a massive historical migration will not be valid, since we may need weeks to move all the data. So, we need a different strategy for massive data migration.
We have created a simple yet effective mechanism for massive data migration automation where we provide the following artifacts:
- A simple framework, leveraging DBcloudbin configuration engine and DBcloudbin operations & activity dashboard for the foundational pieces of defining the migration plan and monitoring it.
- A set of automation scripts that can be used to configure and automate the migration process, while feeding the results to automatically update the monitoring dashboard with the progress and potentially any issues that would require further analysis or troubleshooting.
The method, in a nutshell, is:
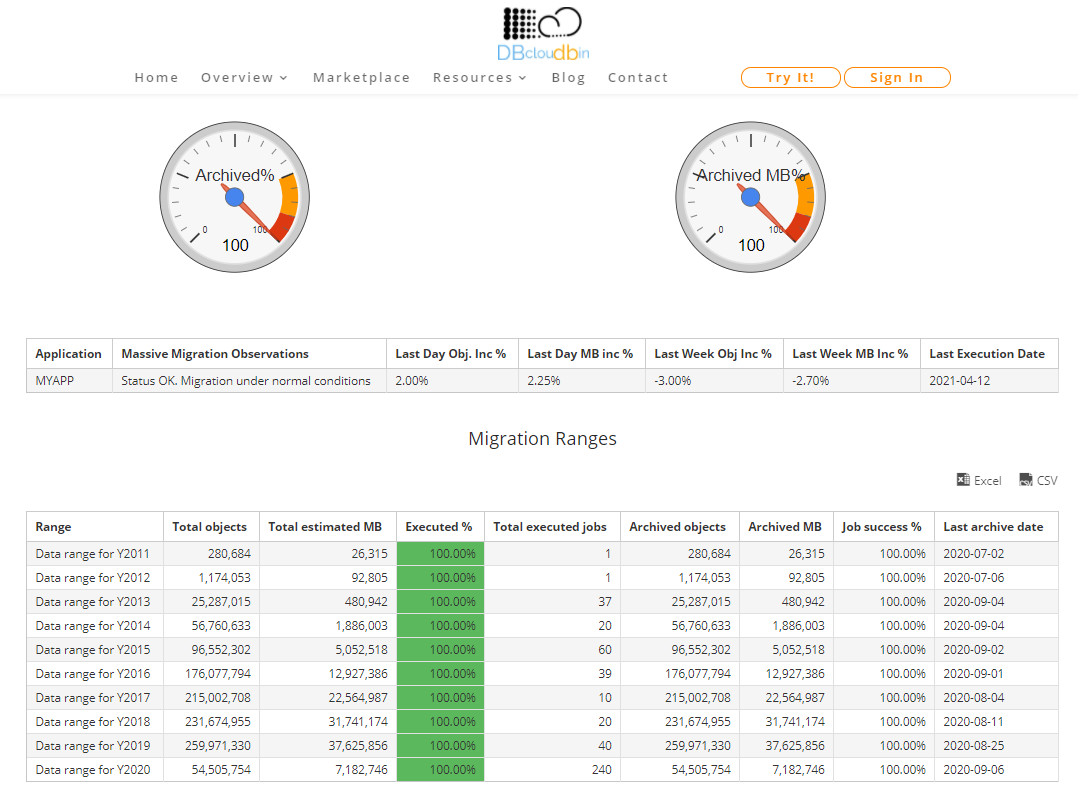
- We should analyze and split our to-be-migrated data by batches. This is not strictly required, but very convenient for monitoring and scheduling purposes. For example, we can define batches by historical criteria (documents from year XX). Once identified, we can create an csv file with the batches list, including inventory data as the total number of objects and total data volume per batch. This is easily created with a simple SQL query through your dataset. With that csv file we can ask DBcloudbin support team to setup the Massive Migration Dashboard with our batches definition.
- We download the massive migration framework from the link provided by DBcloudbin support in the response to the previous request. The framework comprises basically a simple user guide with the parameters to configure in our DBcloudbin environment (they are regular parameters with just specific id’s that start with the prefix “x.” and help us to tune the framework behavior (we will explain it later). So we simply leverage the high available, distributed configuration engine of DBcloudbin for setting the relevant parameters for our migration strategy. This way, we can scale horizontally our implementation with additional DBcloudbin nodes and automatically they will handle and share all the migration settings. This is very important for quickly adapting our migration throughput to our expectations depending on the computing power we have available (we recommend using virtualized infrastructure for additional flexibility).
- Configure the massive migration script (from the framework) for daily scheduling in our DBcloudbin nodes (usually in a simple cron configuration). Since the script will use the settings at the configuration layer, it is basically inmutable and you are not expected to change the cron configuration during the whole migration project.
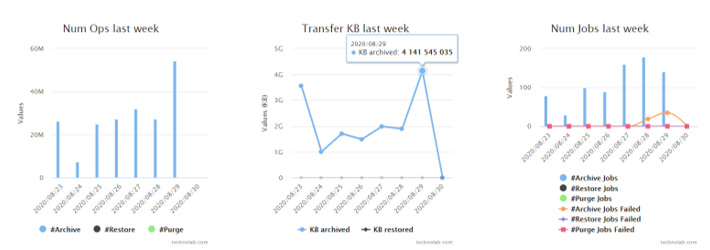
- Test and monitor the logs. If all is OK, our daily migration runs will be automatically consolidated in the Massive Migration Dashboard in our DBcloudbin website customer area (it is provisioned when we request the framework in the step 1). There, we have a simple but informational dashboard on how our migration tasks are doing, the migration rates per batch, the failed jobs and the expected complete time.
Configuring the migration settings
As described above there are a series of configuration settings that we can use to customize how we want to handle the massive migration:
- Active/Inactive: This is a global switch that we can use to stop/restart our migration jobs. This way, we can temporarily stop the migration in all our migration nodes (that may be many) from a central point.
- Filter: This is where we define the logical expression for the objects that define the active batch. If we want to migrate objects for the batch “Year2010” that represents the historical documents from Y2010, we need to define here the ‘where’ clause in our data model that would select the documents for this year (may be something like “EXTRACT(year FROM document.creation_date = 2010)” ).
- Batch: The batch id should match the filter criteria by one side and the batch id we defined in our csv of batch definitions. So, if we decided to split our batches by historical year of data and named in our csv file the 2010 batch as “Y2010”, this parameter should be set as “Y2010”. This way, the DBcloudbin massive migration backend is able to identify this migration statistics to the specific batch and aggregate the statistical data in the migration dashboard.
- Core settings: There are a number of additional settings that will usually not be changed during the migration project (but they can be modified when required, of course):
-
- Table name: The table that contains our to be migrated data. We should configure the engine in a ‘per-table’ basis if we have more than one.
- Migration window duration: We can set the maximum allowed time for a migration run. This way we can configure the process to run only in low workload periods (e.g. nightly runs). The framework will automatically stop and start again the next day at the point where was interrupted and statistics will be aggregated without any manual intervention. This can even be tuned for labour and weekend days to configure different migration windows.
- Number of workers: We can define the parallelization level for each migration job in order to tune the migration throughput depending on the computing and networking capacity of our environment. This may also require some tuning depending on the average object size of our data (the smaller the object the better a high number of workers for maximize throughput). DBcloudbin support will provide guidance on this.
- Log files directory & options: Where we want to store the detailed activity and error logs (and if we want to log performance counters for tweak or troubleshoot performance issues). This will be normally used only for detailed troubleshooting of migrations errors that are recorded in the Migration Dashboard.
- Errors threshold: In massive highly parallelized migration jobs is normal to receive errors from the object store platform we are using for migrating the content to. DBcloudbin is very conservative in errors and, by default, a job is aborted if any error is produced. In massive migration jobs where we are executing jobs that are expected to work during several hours this is not convenient (an object write error does not produce a specific problem, the transaction is rolled-back at database level and the object keeps secured stored at the database). This setting will allow us to define a higher threshold sol we will only consider a migration job as ‘failed’ if it trespass this threshold.
Using this framework we have successfully executed massive data migration projects. If you want to check in greater detail one example, we suggest requesting our Billion+ objects project whitepaper, where it is technically described the migration of a large Exadata platform with more than a billion objects.

by | | blog
In a previous post we discussed about the potential use of DBcloudbin in a reverse way: not for moving content to Cloud but to make Cloud content available to regular (potentially legacy) apps through its relational database. In this new post we will explain in greater detail the technique, with a sample app using Oracle.
The “nibdoulocbd” project consists of using our DBcloudbin solution in an reverse way, to provide our applications with access to documents that we already have stored in the Cloud, with minimal modifications in our application and in our data model. Let’s go with the details…
To carry out this “reverse re-engineering” process, we have selected one of the demo applications provided by the Oracle APEX development platform, but this process could be carried out on any of our applications running on Oracle or SQL Server. For simplicity, we configured an Oracle APEX environment on Docker; you can follow the following tutorial.
Once we have configured our environment with Oracle Apex 5.4 with a workspace called DEMO, it is time to get down to work. The first thing we will do is access our DEMO workspace through the APEX URL, in our case http://localhost:8080/apex/:
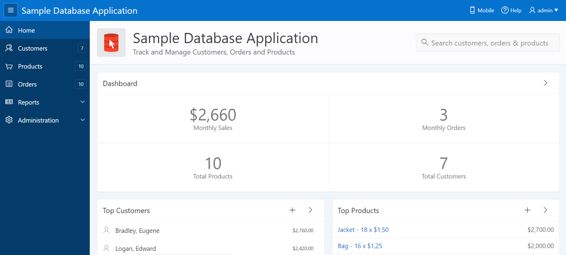
We see the application on which we will base this example “Sample Database Application” that is a sample business application able to manage sales orders (if it does not appear directly, you can install it from the Packaged Apps tab).
Data Model modification
APEX is obviously designed for easy handling of data through the database, but at this point we do not have an attribute (a BLOB type) in the database representing our external Cloud content, so we will have to modify our data model to treat binary data. We would like the user to be able to access the purchase orders in PDF format that we have stored in a S3 bucket in the Cloud from the “Orders” tab in our application; this way our application will handle in the same tab the ‘order data’ already processed with the pdf that we have received with actual order document. This seems a good feature to have.
For this, the only necessary modification in our data model will be to add the necessary fields to the DEMO_ORDERS table to achieve this purpose. This will be as simple as executing the following SQL statement from our preferred SQL client on the DEMO schema.
ALTER TABLE DEMO_ORDERS ADD ( CONTENT BLOB NULL );
Application Modification
NOTE: This is not required in a regular DBcloudbin implementation. In our “flipped over” sample scenario we need it because our application is not currently handling documents (binary content), so we need a minimal application enhancement.
In this section, we will modify our Demo application so that it is able to access and show the user the data “stored” in the columns that we added to our model in the previous step. To do this, we access the APEX App Builder menu. After selecting the edition mode of our application “Sample Database Application”, the design window of our application will appear.
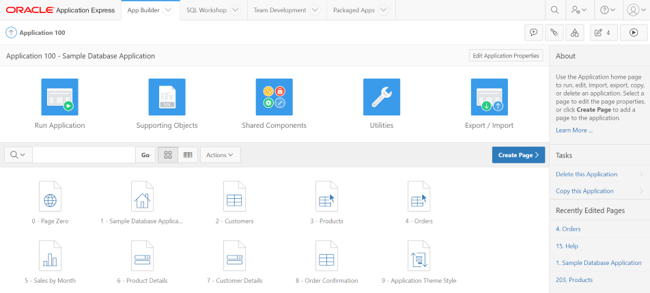
We select the page to modify, in this case our “Orders” page. Once inside the page designer, we will select the Content Body / Orders section, where we will modify the SQL query to show a new column on the page with the link to our PDF documents. We add the following line to the existing SQL statement, which will allow the application to have visibility of the new CONTENT column:
… o.tags tags, sys.dbms_lob.getlength(o.content) content from demo_orders o, …
We save the modifications and the new CONTENT column will appear as part of the Content Body of the “Orders” page. When selecting this field in the properties screen we will see the following values:
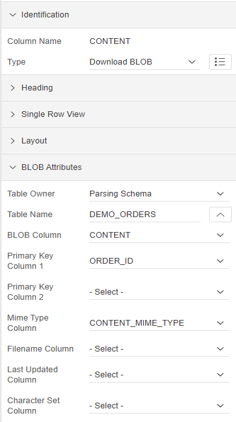
With these simple steps our application will be ready to access documents stored in our database. But, as we commented previously, the idea was not to access the binary data directly in our database, but rather that what we wanted was to access our documents stored in the cloud, and thus avoid the loading in our database , occupying a huge and unnecessary amount of space in it. This is where DBcloudbin comes into the picture, after a quick and simple installation (you can find how to carry out said installation in the following link), and by selecting the DEMO_ORDERS table as the table managed by the solution, we can access the data of our storage in the preferred cloud (Amazon S3, Google Cloud, Azure,…).
To finish this short tutorial and have access to the cloud data, we will have to perform two last actions:
The first, and as part of the DBcloudbin installation / configuration process, we must modify the configuration of our application so that it uses the new transparency layer generated by the DBcloudbin installer (previously it must have been made visible to APEX from its administration panel). To carry out this modification in our Demo application, we will access its edition menu, from the “App Builder” tab and select the option “Edit Application Properties”:

Where, within the “Security” tab, we can modify the scheme to be used by the application. Therefore, we will modify this scheme so that the application uses the transparency layer generated by DBcloudbin: DEMO_DBCLDBL. After this minimal configuration change, the application will be using the transparency layer generated by DBcloudbin to access the data, accessing it, in the same way as it did until now (without internal modifications of queries or other hassles).
As a last step, and since the movement of data to the cloud has NOT been managed by DBcloudbin, to have access to them, we must manually add the links to each of the PDF documents we want to access. To do this, we must insert these links in the DEMO_ORDERS_DBCLDBL table, belonging to the DBcloudbin transparency layer. In our particular case and assuming that the name of the PDF documents stored in the cloud is the purchase order identifier, we can make a simple insertion with an SQL statement similar to the following:
INSERT INTO DEMO_ORDERS_DBCLDBL SELECT order_id, ‘/<bucket_path>/’||order_id||’.pdf’ from DEMO_ORDERS;
Where the <bucket_path> is the path in our S3 bucket where the documents are located. Once we have all the links inserted in the transparency layer, the documents will be perfectly accessible from our application as if they were contained within the same database:
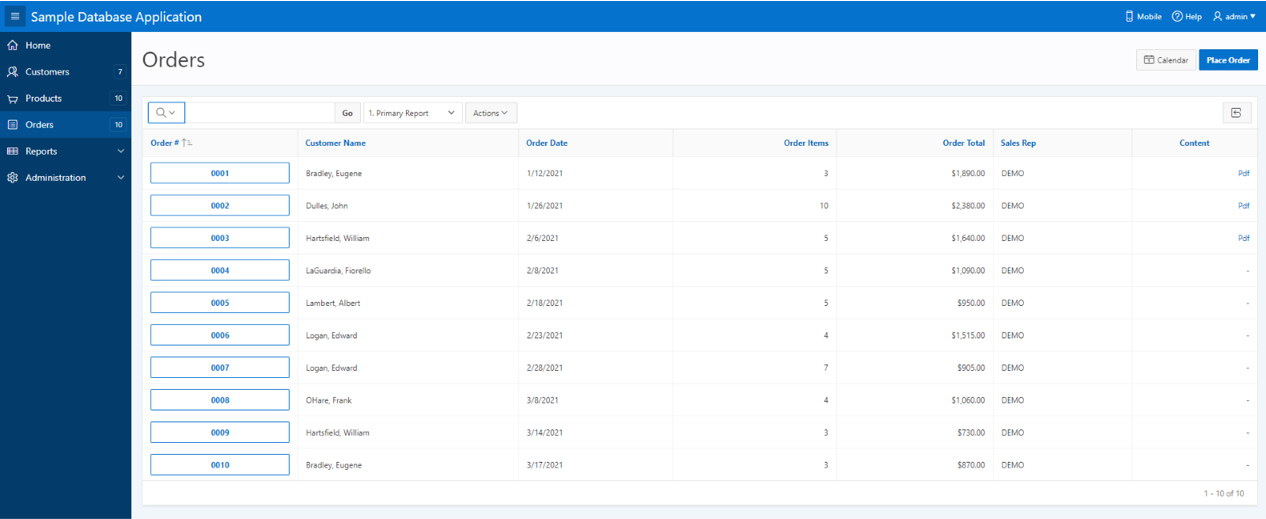
Hope you find interesting this alternative usage of DBcloudbin solution.

by | | blog
Oracle is pushing hard and committed with its Cloud offering, Oracle Cloud Infrastructure (OCI). It is obviously very optimized for the Oracle product set deployment, specifically databases, including the new and flagship Oracle Autonomous DB version, but it has a full portfolio of the common cloud infrastructure services, including an object storage offering.
If you are going to use Oracle Cloud Infrastructure (OCI) object storage as repository for DBcloudbin content, please check the general setup instructions or the installation manual for detailed product setup instructions for a general scenario. In addition we will provide here preparation instructions specific to Oracle Cloud. As of today, DBcloudbin does not support the OCI object store proprietary API protocol so we are going to discuss on how to configure the solution for connecting through the S3 compatibility layer.
We assume you have a basic understanding on OCI terminology and components. A good summary can be found here.
In a nutshell, you need the following:
- Go to Oracle Cloud portal / Core Infrastructure / Object Storage and provision a new bucket (by default in the core compartment). Default settings, are fine (private bucket, versioning disabled, encrypt with Oracle-managed keys).
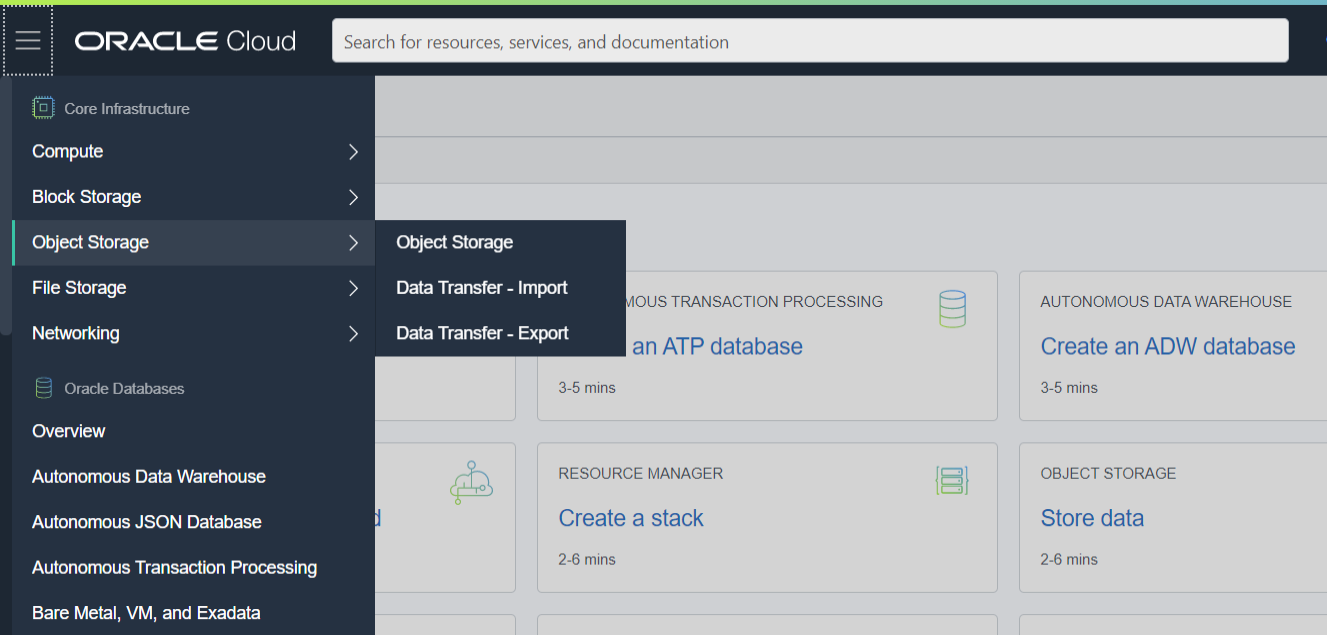
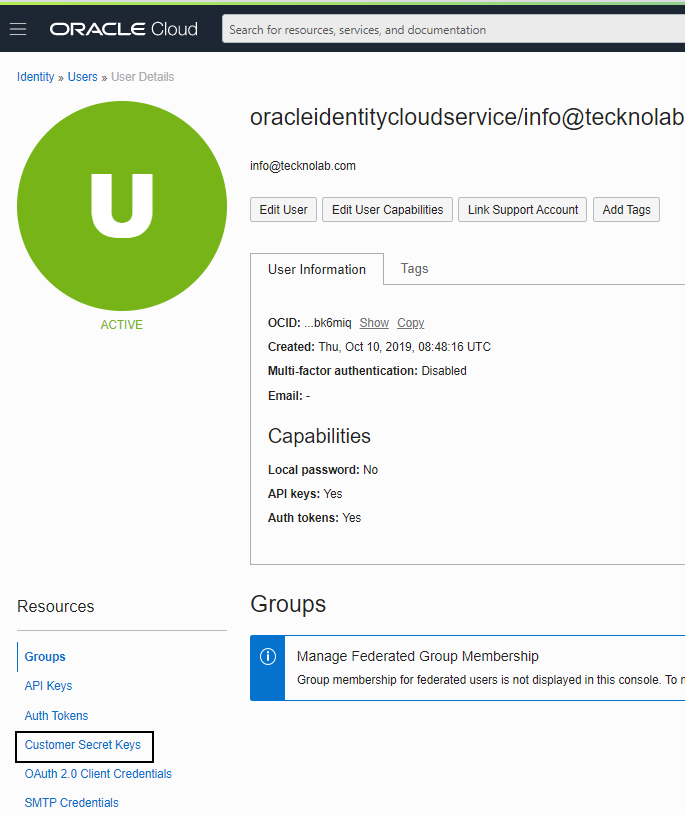
- S3-compatible credentials are required. So, go to user profile in your Oracle Cloud portal (upper right-hand corner) / User settings and select “Customer secret keys”. Create a new key and take note of the Access Key and Secret Key (they are long alphanumeric strings). For security, you may want to do this using a specific user with the strict required capabilities for accessing that new bucket.
- Check the S3 compatible endpoint address (protocol is https). The endpoint address is in the form <object-store-namespace>.compat.objectstorage.<region>.oraclecloud.com where:
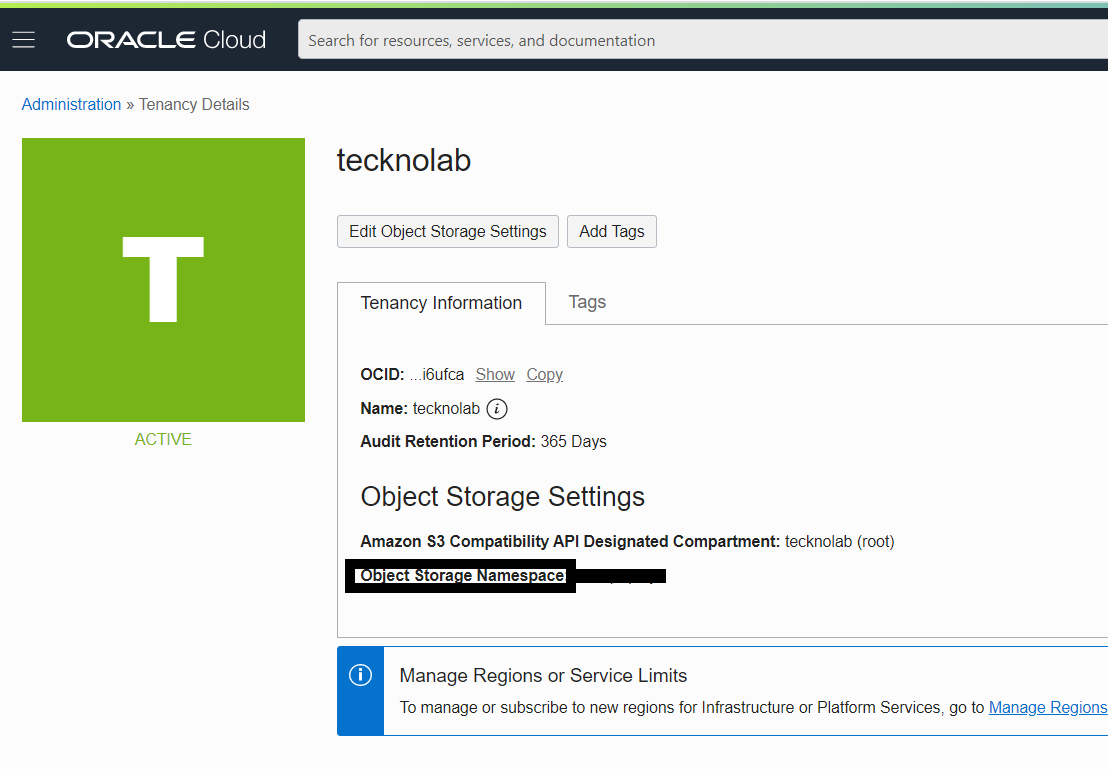
- object-store-namespace is an alphanumeric string that can be found in User profile / Tenancy details.
- region is the OCI region identifier where the object store is provisioned. You can find the region description at the top of your web console. Then, you can go here to find the region id that corresponds to that description.
With all this info collected you are ready for executing the DBcloudbin setup wizard and provide the collected information in the screen where a “S3 Compatible” object store is requested. You will need a DBcloudbin license with S3-compatible service class (by default, the trial one is not; in that case, contact us and request it). The setup will check that it is able to read/write/delete content from the bucket; if any error is found, please write down the error produced and contact support.
In v3.03, we have added support for Autonomous DB in addition to all the regular Oracle DB versions, so you can use our solution with the state-of-the-art, fully OCI based stack, where your application, your database, your DBcloudbin agent and your object store is fully hosted in OCI.
Have fun!.

by | | blog
In this post we want to provide the essential vision on the fundamental question: ” Why DBcloudbin?.” You can read it or just take a look on our video where we describe it animated (or both!).
Any business is generating more and more data every day. Being able to deal with it efficiently and at scale is not only important but crucial. We must do it or our competitor will do it and take us out of business.
IT landscape has robust and scalable database technology that has been created decades ago and is used by our line-of-business applications for storing our precious content: business information. Our apps fuel all the company processes and should be dynamic, efficient and fast. Structured data has been always key, but unstructured data and our capabilities for managing it efficiently will make the difference for the ‘new era’ enterprises. This is the cornerstone of new IT, adding value to the business by managing, processing and adding incremental value to ‘dark‘ data, that information our company has but is unable to leverage it.
We see databases as the key aggregator and consistent repository that fuel our applications, but not necessarily a one-size-fits-all approach for storing all our content is efficient. Layering data at the right tier while maintaining common access, common security and common reference is a better approach in many cases. We need to store and process every piece of data where it is most efficient and secure, while we maintain a unified view, a consistent catalog.
Traditionally, our applications drive and decide how our data is modelled and stored; even how it is consumed. We believe in unlocking data from applications while maintaining consistency. Data must be opened to other alternative business applications for maximizing value. Cost efficiency and incremental value generation are possible. Data processes transformation without long expensive re-engineering is doable.
That’s why we created DBcloudbin and this is what is driving our roadmap and future innovation. Here you can check the details of how it works today.

by | | blog
DBcloudbin 3.03 added some cool functionalities to our solution. If you need a basic understanding on what is DBcloudbin new update, you have a solution overview section that cover the fundamentals and a DBcloudbin for dummies post series that goes one step back using less technical language. For the “why DBcloudbin?” you may want to review our DBcloudbin vision post.
In version 3.03 we are introducing some important features for the solution:
- Built-in job workers parallelization: With version 3.03.x, when creating a new job for archiving, restoring or purging your DB contents, you can include a -numworkers <n> option with the number or workers thread parallelization requested for the job. This, will parallelize the operation at the DBcloudbin agent and with the additional re-engineering performed in the job execution will provide a significant performance improvement. We have measured gains of 30% due to the optimized data locking strategy in parallelization. Now, affected table row is locked by a single thread that passes the actual execution to a pool of workers. This reduce contention at database, improving the throughput.
- Audit jobs: DBcloudbin is designed for moving content from the database to an external object store. In order to maintain access from the application to the externalized content, an internal link to the object is safely stored at the database. We may need at some point in time to check that this link of catalog remains consistent (it is pointing to real objects at the object store). Even more important, if we are leveraging the DBcloudbin heterogeneous replication (where we can define a primary and replica object store, even using different providers and object store technologies) we may want to fix any missing link (this may happen for example, if we add the replica object store when we already have archived content in the primary one, or when we need to swap the existing object store by a new one, potentially from a different vendor). In all this scenarios, audit jobs are the most effective and efficient solution. You can just execute and audit to report any potential inconsistency or add the -fixprimary and/or -fixreplica options to fix unidirectionally or bidirectionally the missing replicas.
- Improved monitoring: DBcloudbin provides a useful cloud-based operational dashboard (in customer area, “Activity Dashboard” tab) where any customer can review the activity, metrics and potential issues of their database managed instances (those where DBcloudbin has been configured). These dashboards are continuosly improved and in v.3.03 we have added activity events that adds interesting indicators (as the customer application archived content reads). However, some customers due to their own policies prefer to build their on-premises, customized operational dashboard. In order to enable this, we have added a logger in our log4j logging engine, called “ActivityLog“, where all the events that are used for populating the centralized dashboard can be captured and directed to any custom log sink (as for example a syslog destination) an processed for generating an on-premises, custom operational dashboard (e.g. using any popular framework as ELK from Elastic). Keep tuned for a specific blog post where we can show a sample on how to generate such a custom dashboard.
- Support of cloud based DB offerings. DBcloudbin can be used with on-premises or cloud based DB implementations. However, some specific cloud offerings come with restrictions on how the privileged users and permissions are managed or exposed to the customer. We have re-engineered our solution to reduce as much as possible the privileged user requirements on implementation (the product did not already need any privileged user for normal operation, only during setup). Starting in v.3.03 version, we support Oracle autonomous DB in Oracle Cloud, Oracle RDS in AWS and Azure based SQL Server Managed Instances (MI), enhancing our customer choices for deploying the solution.
- Java 11 support: DBcloudbin now officially support Java 11. We have managed to overcome the restrictions due to some 3rd party libraries in our setup tool and now there is no restriction to use Java 11 for installing and running the solution.
There are some other minor features that can be checked in our release notes but these are the most relevant.

by | | blog
For a few years now, everyone has been talking about migrating our data and applications to the cloud, and it is something normal, I would say even natural. Once the stigma of security has been saved, and the skepticism on some companies to remove their data or applications from those bunkers called datacenters, the reality is that the benefits offered by the cloud are difficult to overcome in a local environment. Application re-engineering may be required, however (and this is where DBcloudbin can help, as we will see later).
Cost savings is one of the main benefits, savings in physical infrastructure (servers, network elements, …), savings in management and maintenance of the same infrastructure and savings at the software level (for example, avoiding the acquisition of licenses), are some of the most attractive benefits of moving to the cloud. But its benefits are not exclusively monetary, our applications, data, servers, etc., will also benefit from a complex set of mechanisms and flows that will make them more scalable, secure and with high availability.
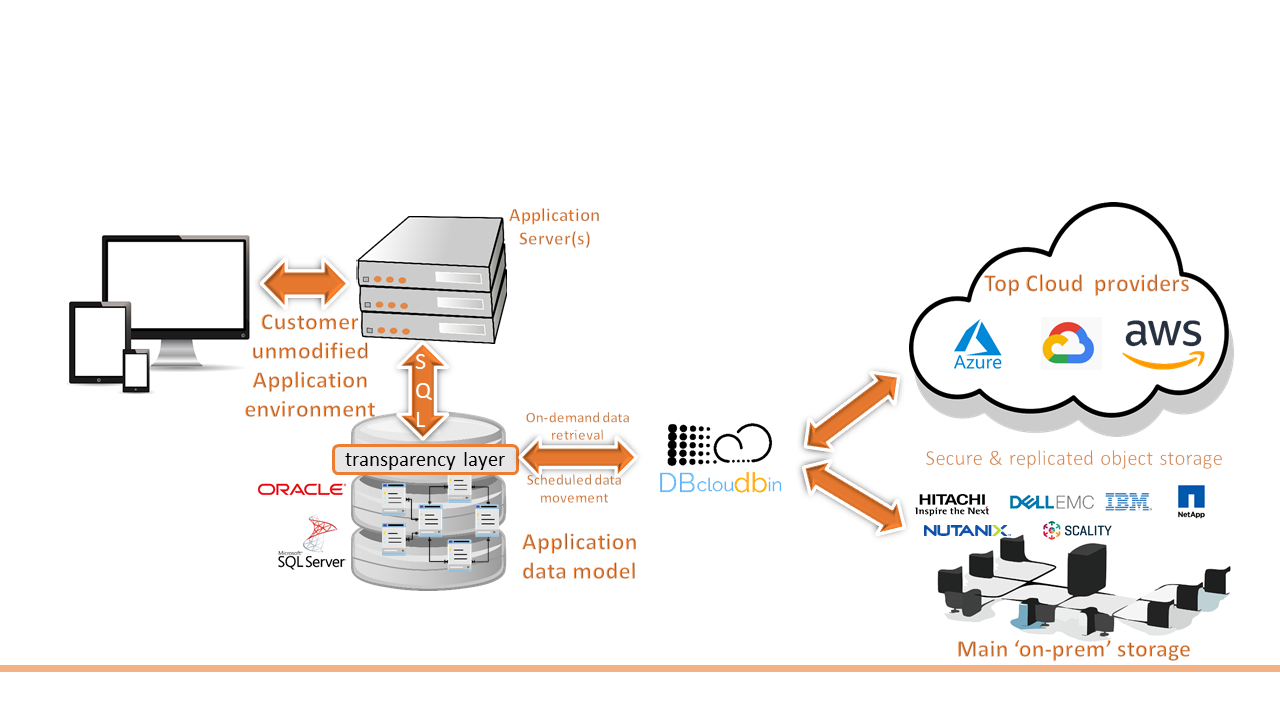
From Tecknolab, and through our DBcloudbin solution, we help our customers to take this step, migrating in a simple, secure and transparent way binary data (documents, images, …) from their databases to the main Cloud providers. Reducing your databases and therefore the cost of infrastructure, management and protection of them.
But what if, for example, we already have data in the cloud in an S3 repository or similar and we want to exploit it from an application outside of it?. The obvious and simple answer would be: make the necessary modifications in your application, to be able to interact with the cloud storage systems, using the protocols and APIs that the same providers provide (Amazon S3, Google Cloud, Azure…). Many times this process of reengineering the data access layer of an application is not easy at all, even sometimes the complexity of the application itself, as in legacy applications, makes it unfeasible. In addition, this type of process usually entails certain costs that are difficult to bear for a project of these characteristics.
Therefore, discarding this point, and based on the principle of simplicity, what is likely is that said application already uses a database, and that, if the application already supports binary data processing, its data is capable of supporting such functionality. This is where the nibdoulocbd (DBcloudbin flipped over) project comes in.
The nibdoulocbd project

The nibdoulocbd project is based on a “reverse engineering” of the cloud data, after which and using DBcloudbin as a solution, we will be able to make our application able to have visibility of this data, without a custom cloud integration; maybe with slight modifications in case it is not prepared for the treatment of binary data (which will always be less expensive than having to fully implement an S3 connector, for example). This process will not move the data from the cloud (a priori it is not what we are interested in, although we could even do it through DBcloudbin if necessary), but it will make it accessible from our application in a transparent way.
An example from the real world.
Let’s imagine that we have in an S3 bucket a series of sales order documents in PDF format, stored with the identifier of the order to which they belong and that we want to be accessible as an attachment to that order from our application, that to this day, it does not handle binary data in our database. Well, after installing DBcloudbin in our system, adding small modifications for the handling of a binary field from our application and by inserting in our database the “links” to the document in S3 linked to each sales order, our application will be able to access said data transparently and without altering the size of our database.
In addition, once DBcloudbin is installed in our systems, it will not only allow us to access existing data in the cloud, but it will also provide us with the tools of the solution working in “non-inverse” mode, allowing us to archive or restore data to and from the cloud that are stored in the database of our application.
In a future post, we will provide a hands-on implementation description of this example. Meanwhile, for more details of the solution, visit https://www.dbcloudbin.com/solution
